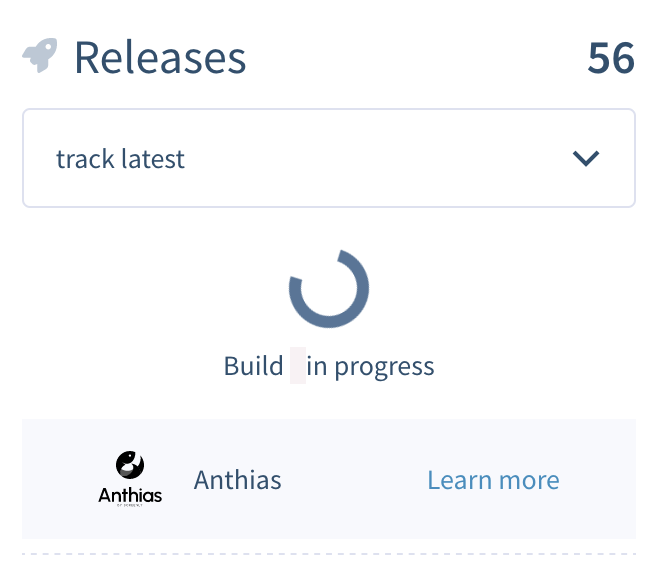
We’ve had a fair bit of issues lately with fleets getting stuck in Build in progress.
For instance, our pi3 and pi4 fleets for Anthias has been stuck in this state for some time now, preventing new builds to be pushed out (as the deploy job will timeout).
Here’s a snippet from the errors we’re getting in the CI/CD pipeline.
Warning: Failed to generate deltas due to an internal error; will be generated on-demand
[...]
[Info] Uploading images
[Success] Successfully uploaded images
[Info] Still Working...
[Info] Still Working...
[Info] Still Working...
[Info] Still Working...
[Info] Still Working...
[Info] Still Working...
[Info] Still Working...
[Info] Still Working...
[Info] Still Working...
Error: Upstream API server/DB error: ESOCKETTIMEDOUT
[Info] Built on arm02
Error: Not deploying release.
Error: Remote build failed
I’m getting desperate here. I’ve tried deploying manually with the below, but still the same issue:
$ balena deploy screenly_ose/anthias-pi3 --nocache --pull --debug [debug] new argv=[/home/user/tmp/balena-cli/balena,/snapshot/balena-cli/bin/balena,deploy,screenly_ose/anthias-pi3,--nocache,--pull] length=6
[debug] Deprecation check: 0.00944 days since last npm registry query for next major version release date.
[debug] Will not query the registry again until at least 7 days have passed.
[debug] Event tracking error: Timeout awaiting 'response' for 0ms
[Debug] Parsing input...
[Debug] Loading project...
[Debug] Resolving project...
[Debug] docker-compose.yml file found at "/home/user/code/screenly/Anthias/balena-deploy"
[Debug] Creating project...
[Info] Everything is up to date (use --build to force a rebuild)
[Info] Creating release...
[Debug] Tagging images...
[Debug] Authorizing push...
[Debug] Requesting access to previously pushed image repo (v2/fb71f9552da59f25bce04f3b26aeb6d8)
[Debug] Requesting access to previously pushed image repo (v2/d851218eac10063e9b2753d01f20f363)
[Debug] Requesting access to previously pushed image repo (v2/29c5ae4e4f516a76bc24265d89fe201b)
[Debug] Requesting access to previously pushed image repo (v2/c33d5c0474d5a81e2c73a23be9cf7186)
[Debug] Requesting access to previously pushed image repo (v2/816dba22d660097f477660a40e62793c)
[Debug] Requesting access to previously pushed image repo (v2/8af23d532bb44a181eb52332834bfd09)
[Debug] Requesting access to previously pushed image repo (v2/8ee514cf79f984b6a03b7e7ee9443649)
[Info] Pushing images to registry...
[Debug] Saving image registry2.balena-cloud.com/v2/06b63e81e92f17bfeb0a735c66c5ebe1
[Debug] Saving image registry2.balena-cloud.com/v2/fabdbd700759a26b6006025441a92066
[Debug] Saving image registry2.balena-cloud.com/v2/10bb10539edd83db90ee9feac3916742
[Debug] Saving image registry2.balena-cloud.com/v2/94d5d671503f18a7944239c5ba41c1d5
[Debug] Saving image registry2.balena-cloud.com/v2/1638bdd46a638ea9e7effbde72f07605
[Debug] Saving image registry2.balena-cloud.com/v2/ac386219bb88e3377221650af54db559
[Debug] Saving image registry2.balena-cloud.com/v2/578bbbf613ceb4c8004ab96b46aa4d0c
[Debug] Untagging images...
[Info] Saving release...
[Error] Deploy failed
ESOCKETTIMEDOUT: ESOCKETTIMEDOUT
Error: ESOCKETTIMEDOUT
at ClientRequest.<anonymous> (/snapshot/balena-cli/node_modules/request/request.js:816:19)
at Object.onceWrapper (events.js:519:28)
at ClientRequest.emit (events.js:400:28)
at ClientRequest.emit (domain.js:475:12)
at TLSSocket.emitRequestTimeout (_http_client.js:790:9)
at Object.onceWrapper (events.js:519:28)
at TLSSocket.emit (events.js:412:35)
at TLSSocket.emit (domain.js:475:12)
at TLSSocket.Socket._onTimeout (net.js:495:8)
at listOnTimeout (internal/timers.js:557:17)
at processTimers (internal/timers.js:500:7)
For further help or support, visit:
https://www.balena.io/docs/reference/balena-cli/#support-faq-and-troubleshooting
I’m pretty certain that this is a server side balena issue.
In short, the problem was the Balena’s worker got stuck somehow and stuck in ‘Failed’ mode and showing ‘Build in Progress’ (see earlier screenshots).
The workaround for this was to instead of using balena deploy [...], use balena push [fleet] --draft and subsequently promote the release in the Balena UI.
This “unstuck” Balena and allowed us to publish subsequent releases.
We’ll look into automating this in our build flow as our deploy method instead.
@mpous, we’ve experienced the similar issue again. I tried the solution provided by @vpetersson, but it didn’t work anymore. (I tried it on my local machine.)
Even on my local machine running balena push is stuch at “Still working…”.
The last thing that I’d do (I’m not 100% sure if it will work) is to delete those releases stuck at the “Running” state.
Looks like I’m not the only one with an issue like this, it seems. I’m encountering a similar problem and have reported this in the CLI repo before, but have unfortunately not gotten a reply in the past 3 weeks.
I also suffer from timeouts when trying to build via balena push and they leave builds stuck in the ‘Running’ state in the web interface. This has been a consistent issue for months and hasn’t gotten better, so I figure I’d throw my hat in the ring to maybe add an extra datapoint here.
It’s quite frustrating when you want to push out a release and end up delaying by a day or more just because Balena’s build system doesn’t work again.
@nicomiguelino could you please let me know what are you trying to deploy? i would like to try to reproduce!
@byteminer thanks for reporting on the CLI repo! The balena team is exploring this and we will keep you posted once. Having said that, could you please share more details of what are you trying to deploy?
I’ll try to create a reproducible example that doesn’t require an NDA to publish, will post here once I have something. I strongly suspect this is an issue with large multi-container builds as I’m building things for Jetson, which necessarily pulls in all of the Nvidia drivers for every container that makes use of the GPU. This quickly leads to multi-container setups that reach 40+ GB in size.
My theory at the moment is that the Balena builders time out when trying to pull the cache images, which then propagates through to the CLI and ends up in a non-informative timeout error.
I have since figured out that I can increase the chance of a build going through by reducing the number of containers (even if the containers I remove from the setup are very small), so maybe it has something to do with the container count as well.